Typing the Neo4j Query API

This blog explores the story behind adding type information behind the
Neo4j Query API. “What’s the Query API?” I hear you
ask. Its a easy and simple way to query Neo4j through your favourite HTTP client. The Query API is
now available on Aura (in beta).
Discord in the Driver’s channel.
Neo4j’s First Interface
HTTP support for Neo4j was one of the first interfaces exposed for accessing Neo4j data (after the Embedded API). However, the HTTP interface has somewhat lagged behind the preferred transport bolt which powers the official and community drivers.
Over the last few years that HTTP support has been slowly rejuvenated, with new functionality being added to the existing Cypher Transactional HTTP API such as limited support for clustering and HTTP/2 support.
The latest improvement is a bigger change. The API as well as its type format has been completely redesigned. For now, it available as “Neo4j Query API” in parallel to the existing API. The Query API supports two different formats:
application/json- the API’s default, which maps Neo4j results directly onto JSON, choosing the most suitable JSON type. This format allows you to quickly query your data with minimal tooling.application/vnd.neo4j.query, which defines a new mapping of Neo4j types onto JSON aimed at more complex interactions with results.
This post focuses on the typed result format of the new API and assumes a basic understanding of the API. If you’d like to get a grasp of the basics before reading this post, check out the wonderful post by the project’s PM Jonathan Giffard.
The Problem
All good solutions must start by correctly identifying the problem. In JSON, the de facto standard for data exchange via HTTP, we have the following native types:
null- boolean (
trueorfalse) - string (
"A mighty string") - number (
1,12.34) - array (
["a", 123, "bunch", true, "of", ["huh"], "stuff"]) - object (
{"im": "an object"})
In Neo4j we have a much richer type system.
Neo4j has types that JSON also has including: Booleans, Strings and Maps, but it also has things that JSON does not,
such as: Nodes, Dates and Points.
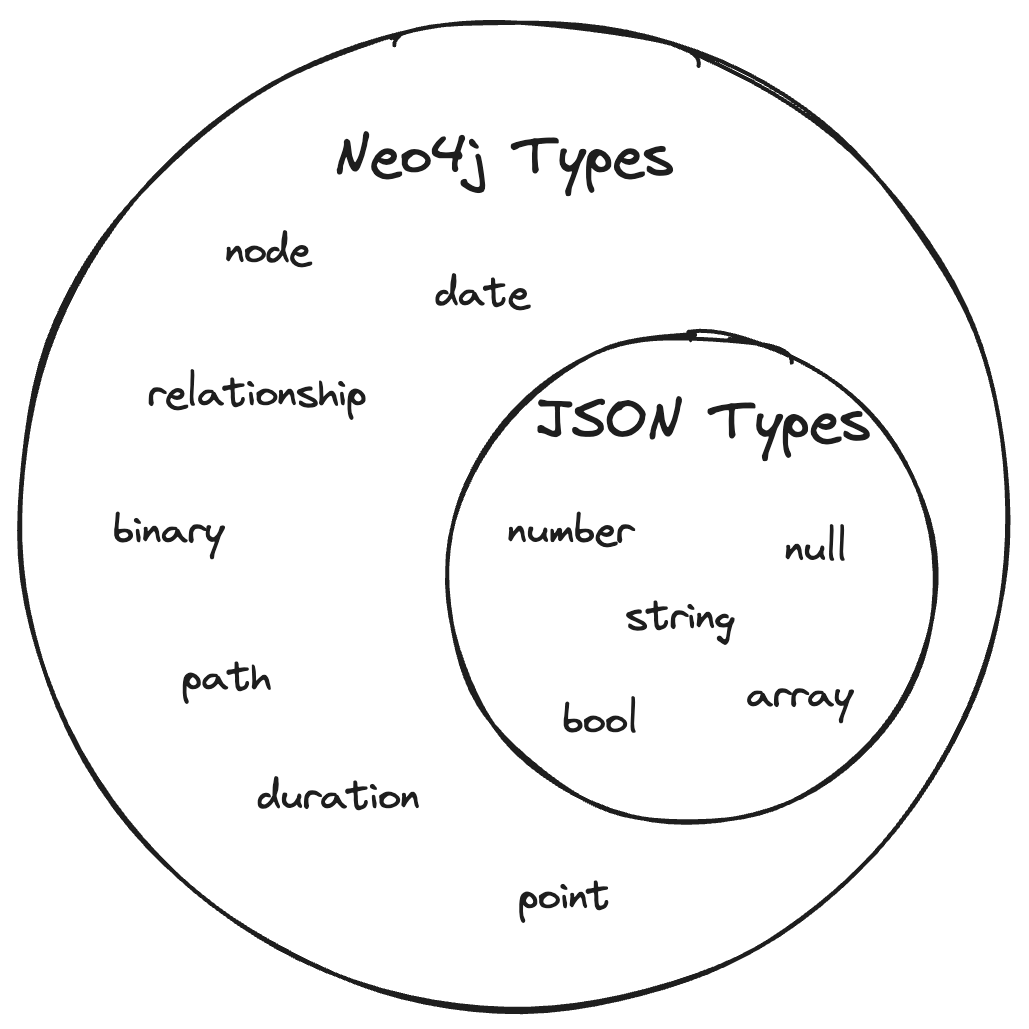
Note: this is a simplified view of the how the types intersect and there are some difference we omit here for brevity.
The problem we have is that in order to interact with Neo4j via HTTP’s preferred type format JSON, we have to introduce a mapping between the two type systems. Since the underlying types between the two systems diverge, and JSON is the format that is missing the additional types, we have to extend JSON so that Neo4j types can be communicated without losing the benefits of the additional Neo4j types.


Why deal with Types at all?
Types also come with operations on these types. For example, if you know you are
dealing with a Node type, then you also know that is has labels that can be retrieved from it (i.e an
operation of labesl() -> [String]. Each of Neo4j’s types come with many useful operations which makes further
processing the results possible.
But didn’t you say the Query API support plain JSON?
Yes, but to do this we had to transform the richer Neo4j types directly onto the JSON types, losing their richness, and
making writing a parser much more difficult. In the application/json format we serialize types such as points into the
most suitable string representation
(in this case Well-known text representation of geometry).
This format is best suited for simple use cases such as: ad-hoc querying, rendering directly to a UI or where it’s not possible to use additional tools or dependencies to further process the response. On the request side, we also would like to insert these Neo4j types into Neo4j and, while this is possible with cypher functions, it would be much better to explicitly use these types in our requests.
So what should the new format look like?
Now that we have fully identified the problem, we can address what a good solution to it looks like. We set ourselves the following design goals for the new format:
-
Human Readability - One of the great strengths of JSON is that it is understandable to read without any extra tooling (save a pretty formatter). This is great for ad-hoc querying since no further processing is needed. It also makes developing with it much easier since you can fire off a request and examine it before solidifying it in code.
-
Machine Readability - As discussed, we want to preserve the richness of Neo4j types and this means in practice processing the results and deserializing them into the native (or custom) types of the calling language. We will expand on this in a later post but for now we understand this goal to be summarized as “Can I easily write a parser with standard tooling in mainstream programming languages?”.
-
Streamability - There’s no reason to restrict the size of data that the Query API can return. Since it might take a while to complete the returning of a large result, it would be great if the results were returned in a way that they can be processed by the client as they become available (i.e. to not wait for the whole thing comes back before processing it).
-
Flexibility - Even after over a decade and a half of development, Neo4j is still rapidly changing with new features such as CDC and RAG support. Most important for this API is that this format needs to be able to adapt to new types.
Where is performance?
Performance is a consideration, but, as you can figure from these criteria, the main goal is ease of use. Neo4j’s performance offering is covered by our in-house binary protocol Bolt which power the official drivers.
Adding Types To JSON
A great starting point on adding type information to JSON can be found in Peter Hilton’s
Blog
but most options here
essentially add a type properties at various points the JSON. The question is where should we put it? We decide to use
Option 3 of having type paired with value in an JSON object representing the results:
{
"type":"Integer",
"value":"1"
}
Let’s look at how this solution stacks up against our requirements:
-
Human Readability - Whilst, as Peter points out, some reduction in readability from the additional nesting of values (this may not look too bad in this example but remember this would multiply for each nested value), it is still readable and intuitively it is clear which what is a type and what is a value. Mostly-Check.
-
Machine Readability - a parser would only need to check the value of what is in the
typefield and so this lead to a simple if block. But there’s no need to completely write a parsers from scratch. Many parsing libraries in many different languages support this style of adding type information making writing a parser quite easy. Check. -
Streamability - Since types and values are nestled nicely together there’s nothing that prevents us from streaming values independently of each other. Check.
-
Flexibility - Adding a new type is as simple as introducing a new String for that type. Check.
Introducing The New application/vnd.neo4j.query Media Type
We introduce a type/value pairing object which can be returned when adding
application/vnd.neo4j.query as the Accept header:
curl --location 'http://<your_server>/db/neo4j/query/v2' \
--header 'Content-Type: application/vnd.neo4j.query' \
--header 'Accept: application/vnd.neo4j.query' \
--header 'Authorization: Basic <your_auth_token>' \
--data '{"statement": "RETURN 1"}'
{
"data": {
"fields":["1"],
"values":[{
"$type":"Integer",
"_value":"1"}
]},
"bookmarks":["..."]
}
Wait!? What’s with the $ and _? In general it’s good to make it clear when a JSON property is part of the result and
when a property is considered meta-data and these two prefixes make it clear these properties are to be treated differently.
We could exclude these but Neo4j is also in the unfortunate position that we would have a clash of names with Neo4j’s node
type having a property called type. Best to avoid the confusion and potential mistakes.
And that’s all that’s to it. Of course we now have to define what each of the types’s string tag and the format of the value but we leave this for our documentation.
Can I push data into Neo4j using this format?
The problem we describe earlier in this blog also applies when we want to push data into Neo4j. The lack of types available to us in JSON make it impossible for Neo4j to understand what type you are trying to store. For example take the following request:
curl --location 'http://<your_server>/db/neo4j/query/v2' \
--header 'Content-Type: application/json' \
--header 'Accept: application/vnd.neo4j.query' \
--header 'Authorization: Basic <your_token_here>' \
--data '{
"statement": "RETURN $zonedDateTime",
"parameters": {"zonedDateTime": "2015-11-21T21:40:32.142Z[Antarctica/Troll]"}
}'
{
"data":
{
"fields":["$zonedDateTime"],
"values":[
{
"$type":"String",
"_value":"2015-11-21T21:40:32.142Z[Antarctica/Troll]"
}]
},
"bookmarks":["..."]
}
It’s impossible for Neo4j to know that you wanted a ZonedDateTime and not a String. It is possible to tag the Cypher statement
with dateTime() procedure and then it will be read as the correct type but then you miss out on the security and performance benefits
of parameterising your queries. Fortunately you can still parameterise your query by using application/vnd.neo4j.query as
input by setting Content-Type header with that value:
curl --location 'http://localhost:7475/db/neo4j/query/v2' \
--header 'Content-Type: application/vnd.neo4j.query' \
--header 'Accept: application/vnd.neo4j.query' \
--header 'Authorization: Basic <your_token_here>' \
--data '{
"statement": "RETURN $zonedDateTime",
"parameters": {"zonedDateTime": {"$type": "ZonedDateTime", "_value":"2015-11-21T21:40:32.142Z[Antarctica/Troll]"}}
}'
{"data":{"fields":["$zonedDateTime"],"values":[{"$type":"ZonedDateTime","_value":"2015-11-21T21:40:32.142Z[Antarctica/Troll]"}]},"bookmarks":["..."]}%
{
"data":
{
"fields":["$zonedDateTime"],
"values":[
{
"$type":"ZonedDateTime",
"_value":"2015-11-21T21:40:32.142Z[Antarctica/Troll]"
}]
},
"bookmarks":["..."]
}
Give application/vnd.neo4j.query a try today on Aura and be sure to reach out with questions
or feedback on Discord.
Acknowledgements
In this first post I thought it would be fitting to mention many folks who have helped to make the Query API a reality. My fellow colleagues Michael Simons and Gerrit Meier for the initial PoC that kicked off this whole thing and their continued support throughout the project. Dmitriy Tverdiakov who helped out with a key piece of architecture. Grant Lodge who has reviewed many of my nonsensical PRs. Antonio Barcelos who helped to validate this type format by writing the first non-java parser in javascript. A big thanks to Waiariki Koia and the folks in the Aura who are helping to bring this show onto the Aura stage. Stefano Ottolenghi for the great work putting the docs together. Andy Heap and Ivan Fulöp for their patience and support during some sticky moments. As mentioned already the project’s PM driving this whole thing forwards Jonathan Giffard. And last but not least Richard Macaskill who was the previous wonderful and kind PM on this project before he sadly passed away last year.